Why retrieval quality is becoming the defining challenge in agent architecture
Agentic systems usually have two jobs: build context, then use that context to produce an answer or action.
Many failures that look like LLM problems start in the context-building step. The answer the LLM gives is limited by the context it was given or it finds through tool calls. If the agent model cannot find the right sources then improving the generation model will not improve the overall system.
A client, Specstory, wanted to give users the ability to ask questions from agent history. For example, why a team chose Authlib for authentication and what alternatives they considered. The chatbot needs the right prior conversations, decisions, and tradeoffs from a large corpus of coding sessions. The model and system prompt help only after those chat turns are retrieved and in context.
If retrieval ranks implementation snippets above the discussion where the team weighed alternatives, the agent can still produce a confident answer. It may find code that imports Authlib and a few inline comments, then describe the decision from implementation evidence instead of the actual tradeoff discussion.
The same pattern showed up in an AnkiHub operator review in our private community. A request for help studying based on lecture slides only works if the agent’s tool calls retrieve the right flashcards. The hard part is not finding any related cards. A lecture on the function of the heart may match hundreds of cards. Ranking decides whether the core cards make it into context, or whether the system has to raise top_k and flood the prompt.
The exact setup changes by product. The context-building step might use local search, semantic search, web or API calls, or database queries. It might be handled by an agent, a fixed workflow, or application code. The process stays the same: gather the right context, then generate from it.
For example, a coding agent runs rg, opens files, reads logs, and inspects tests before writing a patch. A research agent searches the web and internal notes before writing an answer. A study assistant searches deck facts and user context before suggesting what to learn next.
When context building fails the symptoms look like generation failures.
| Symptom | Retrieval cause |
|---|---|
| Hallucination | The answer source never made it into context. |
| Context rot | Low recall forces a high top_k, so noisy results fill the context window. |
| Latency | Weak retrieval causes more tool calls, larger candidate sets, and bigger context windows. |
A better model helps with reasoning and writing, but it cannot give a better answer without the right context.
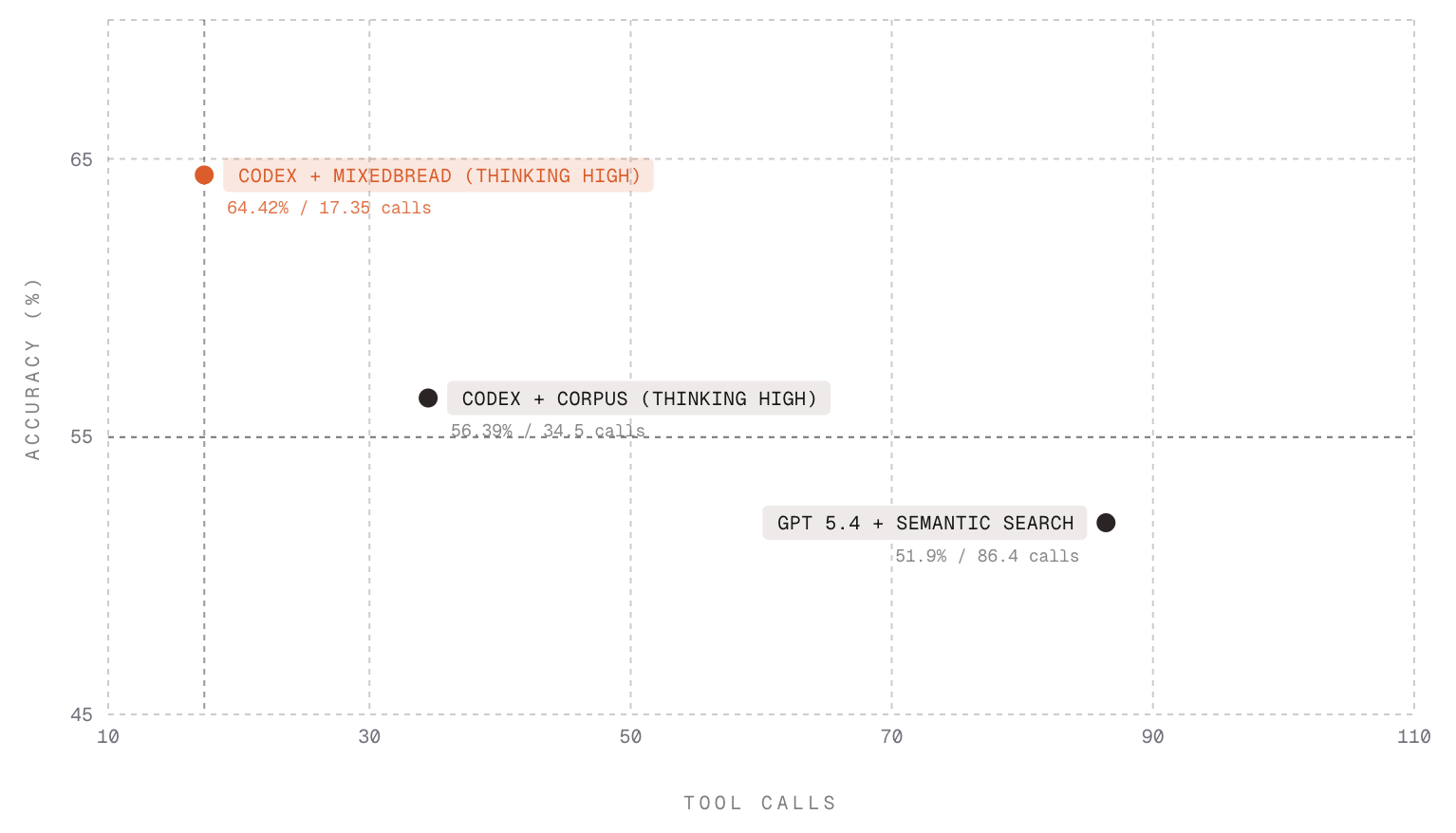
The Mixedbread OfficeQA-Pro Eval shows the same pattern at benchmark scale. OfficeQA-Pro uses 89,000 pages of financial documents, dense tables, scanned PDFs, and questions that require reasoning across documents. Giving Codex better search tools reduced tool calls and improved answer quality.
Plain text tools like grep and rg work (ish) over flat code files. They do not work well when context lives in PDFs, tables, chat histories, multi-modal inputs, web results, and permissioned data. In those cases the agent needs retrieval that can combine exact terms, meaning, metadata, permissions, and ranking quality.
Retrieval needs traces and evals
Once retrieval enters the architecture, the next question is whether it finds the right information.
For that you need traces and evals. For each retrieval step the minimum trace is the input, the outputs, and a way to label whether each output was relevant.

For a coding agent using rg the input is the command, the output is the returned snippets, and the label says which snippets helped, which were noise, and which relevant files were missing.
For product retrieval the step might be BM25, semantic search, hybrid search with reranking, a generated SQL query, or something else. Capture the query or arguments, the returned documents or chunks, and whether those results were helpful.
Trace each retrieval step by itself, then evaluate the full context-building pass. The local trace answers “Did this query return useful material?" The full trace answers “Did the system collect everything the model needed before generation?" If it did, failures are a generation problem. If not, it's a retrieval problem.
You cannot know where the failure started or what to fix without traces.
Different failures need different fixes
"Improve retrieval" is too broad to be useful because different problems have different solutions. If a relevant document is missing the trace should show where it disappeared: query building, retrieval, filtering, ranking, or final context assembly.

The failed step plus what the trace shows tells you what change to make.
| Failed step | What the trace shows | Change to make |
|---|---|---|
rg / grep | A conceptual query returns literal matches and misses the relevant files. | Add semantic search over files or chunks, or generate better keyword queries before calling rg. |
| BM25 | The query uses the right concept but different words from the source material. | Add semantic search, synonyms, or query expansion. |
| Semantic search | Exact names, error strings, document IDs, or domain terms are missing from the results. | Add a keyword or BM25 path, or boost exact term matches. |
| Hybrid retrieval | The relevant passage is ranked 7th, but the context only takes the top 5. | Add or tune a reranker, or raise candidate top_k before reranking. |
The right fix depends on what the system was trying to retrieve. A decision-history question needs the decision, the alternatives, and the chats where the team worked through them. A study question depends on the lecture material, deck metadata, semantic matches, and the user's study context.
The architecture
Once you trace individual retrieval calls, the full architecture has a simple shape: fan out to context-building tools, then fan in to generate the final output.

The retrieval layer might be a search engine, a vector database, a SQL query, local file tools, a web search API, or a custom service. The pattern stays the same: build candidate context, narrow it, rank it, assemble it, then generate from it.
Agents need the same search controls humans use
Semantic search compares embeddings (numbers that represent meaning). It helps when wording differs but most retrieval intents also depend on structured constraints. A meeting search box can use semantic search over transcripts and notes, but a useful interface also lets someone filter by person, date, project, and source. A finance search may need the latest filing, a specific quarter, or an official source in addition to the closest semantic match. In e-commerce, the best semantic match for "32x30 cargo pants" may be a product that is out of stock. The system still has to decide whether to hide it, return it with a backorder note, or show it so the user can check later. That product decision is a retrieval decision because it changes which candidates reach the agent.
In a chat interface those controls are in the tool schema, query planner, or app logic. If an agent runs the search it needs arguments for the same constraints a human would set with filters, sliders, tabs, and sort menus.
A retrieval system usually needs several controls working together:
| Control | What it does | Example |
|---|---|---|
| Exact match | Matches names, IDs, error strings, quoted phrases, tickers, or product codes. | Find EADDRINUSE, Authlib, or a specific SEC accession number. |
| Semantic match | Finds related content when the wording differs. | Find the meeting where the team discussed authentication tradeoffs. |
| Hard filters | Removes invalid results before ranking. | Limit by tenant, permissions, person, date range, size, or stock status. |
| Sorts | Orders candidates by a structured field. | Prefer newest, latest filing, lowest price, highest rating, or recency. |
| Ranking | Scores candidates by likely usefulness for this request. | Combine semantic match, exact match, freshness, source quality, and use. |
| Reranking | Uses a slower model or scorer on a smaller candidate set. | Compare the query against the top 100 candidates before returning 10. |
Here, a chunk means a small piece of source content, and a candidate is a chunk returned by the first search step. Ranking is the scoring step that orders those candidates. Context assembly then chooses which chunks and structured fields go into the model prompt.
Better ranking improves precision, which means a larger share of the returned chunks are useful. If the relevant chunks are near the top, the system can pass fewer chunks into the model, spend fewer tokens, reduce latency, and give the model less noise. If the right chunk is ranked 40th and the context only includes the top 10, the system behaves as if retrieval missed it.
People and agents use the same basic search path: ask for results, inspect what comes back, and decide what to use. A person can skim ten search results, compare titles, snippets, dates, domains, and URLs, and decide whether the result set looks right. They can open the third result, ignore the rest and search again with a better query. An agent usually gets a bounded set of returned documents and reasons from what’s in context. If the right source falls below the cutoff the agent may answer from partial context. To avoid that the system has to retrieve more candidates, run more searches, or pass more evidence into the model.
A missed document can change what the agent searches for next. Suppose someone asks why the team chose Authlib. If the first search misses the transcript where the team compared Authlib with alternatives, the agent may search the codebase instead. It finds imports, callback handlers, tests, and maybe a comment. Then it asks follow-up questions about OAuth configuration. The context starts to look complete, but it supports the wrong answer. It explains how Authlib was used and why it makes sense in the codebase, not why the team chose it.
But ranking cannot repair every search problem. If the agent failed to ask for the latest filing, a reranker may faithfully choose an older document with a closer wording match. If the tool has no date_range, person, source_type, size, or in_stock argument, the model has to put hard constraints into the search text and hope retrieval infers them. A hard filter gives the model less to infer and makes semantic search more reliable.
Scale changes the retrieval problem
Search systems already have tools for this: indexes, filters, facets, sorts, caching, bounded reranking, and freshness jobs. Agent systems need the same discipline.
A human might search, adjust a date filter, scan the first page, then search again. One agent request can do that many times in seconds: rewrite the query, run keyword and semantic search, inspect thin results, issue follow-up searches, fetch sources for citations, and ask for more context before answering. With many concurrent users or agents, the retrieval layer can become a bottleneck.
Humans often wait through a slow search if the result is good. Agent systems often turn slow and uncertain search into more work. When ranking is weak, teams compensate by raising top_k, running keyword and semantic searches in parallel, adding reranking, fetching more source documents, and passing larger evidence bundles to the model. That can improve answers but it moves the cost into tokens, latency, and retrieval load. Better ranking lets the system return fewer, better candidates instead of making every request carry a larger pile of possible evidence.
With a small corpus you can still search comprehensively quickly and cheaply even with fully agentic approaches. That's what I recommend when you're starting and don't have much data. Don't add complexity until you need it. But with millions or billions of chunks every extra retrieval call, candidate, ranking pass, and returned token adds up quickly.
Multi-stage retrieval is the production shape
Most production systems should split retrieval into stages even when the UI is a chat box.
| Stage | What happens | Trace question |
|---|---|---|
| Search argument construction | The app or agent turns the request and state into query, filters, and sort. | Did it ask for the right content with the right constraints? |
| Candidate generation | The system finds plausible chunks from text, vectors, or structured data. | Did the right source enter the candidate set? |
| Filtering | Permissions and product constraints narrow what can be returned. | Was the source correctly excluded or wrongly lost? |
| Sorting | Structured fields order results when order matters. | Was the latest, cheapest, highest-rated, or current item surfaced? |
| Ranking | The system scores the candidates by usefulness for this request. | Was the source present but ranked too low? |
| Summary return | The system returns only the fields the agent needs. | Did the app receive usable evidence and provenance? |
| Context assembly | The app selects, formats, and budgets evidence for the model. | Did useful evidence get dropped before generation? |
| Evaluation | Humans or automated checks label whether the retrieval path worked. | Can the team turn the failure into a specific fix? |
Each stage leaves a different repair path. If the agent chose the wrong filters, changing the embedding model will not help. If the latest document was available but the tool never sorted by date, the fix belongs in the search arguments or retrieval API. If the right source was present but below the cutoff, the fix belongs in ranking. If the right source came back but was dropped before generation, the bug is in context assembly.