Memory: chats, wiki, skills, and sources
My agent should learn from mistakes and get smarter over time (at least on the types of problems I work on). But agents are amnesiacs, they forget everything every session. AgentKB is designed to let the agent see things I’ve learned or that it’s done before, so that it can do the same kinds of things quicker. I’m open sourcing agentkb, the system I use to do this.
Agentkb currently stores four types of information. Agent chats, X posts, wiki, and skills as plain text markdown directories. I call each information directory a store. Each store is searchable. All of it integrates with my agents (mostly Claude Code, and Pi).
Loading...
I thought about delaying this post, because it's nerve-wracking to share so early/messy/buggy. But it's useful in my day-to-day.
Why
I used to keep all knowledge AI needs in agent skills. An agent skill has two parts. The first is a prompt for when to read more. For example “Read Prompt A when asked about video editing”. The agent ALWAYS sees this prompt. The second part is a more detailed prompt that is read only when the user asks about video editing (based on the model’s discretion).
It worked for a while, but the skills got fat and hard to read. Preferences, corrections, and lessons from things the agent did wrong all stacked into the same files. The agent would read everything in the skill, but much of it wasn’t relevant to its current task. I tackled this by splitting into separate skills, and eventually had hundreds of them that it would read a combination of. I was confused, the agent was confused, I couldn’t maintain the content quality.
I wanted to rebuild using a combination of four ideas.
- Late-interaction retrieval
- Specstory agent-transcript saving
- Karpathy's LLM Wiki post
- Pi Extensibility
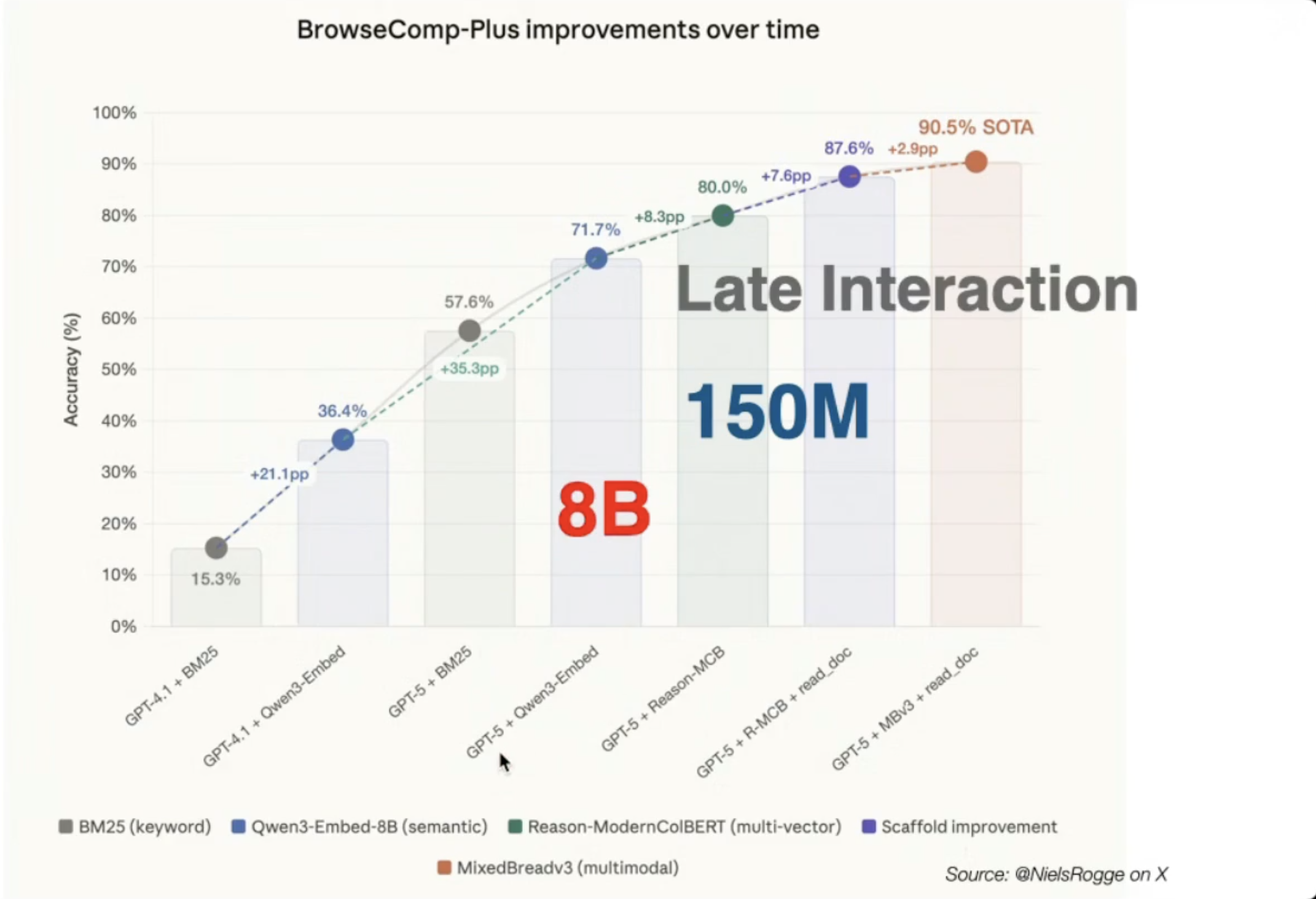
Late-interaction retrieval got good enough to rely on. For example, see the trajectory on BrowseComp-Plus.
Specstory agent-transcript saving I have written before about using Specstory agent history. My first pass at memory was an analysis of ~ 2000 agent transcripts, which found fascinating insights that were too aggregated to be of practical use on specific tasks.
Karpathy's LLM Wiki post. Markdown was the right format. Agents can read/write it reliably, it’s easy to chunk and search over, and it’s great for my readability.
Pi extensibility. Pi lets me control what enters the agent's context more than other harnesses. It gives custom tools, custom tool renderings, hooks, and control over the system prompt.
What I Actually Use It For
Giving agents a memory. Agents query the knowledge base directly when they need context. Claude Code and Harpy (my Pi harness) both use the same stores.
Finding what I already did. Search the wiki for distilled notes and chat history for raw sessions when I need to remember how I handled something before.
These combine with skills. Skills are thin and procedural business logic. The knowledge base holds general gotchas, knowledge, taste, opinions, and preferences.
For example, the writing skill I created for agentkb contains information about how I approach writing step-by-step. Information about who inspires my writing, what I like about them, and my style lives in the wiki.
Same for coding. For example, the skill holds my testing approach, and wiki holds setup notes for e2e testing with Clerk.
How Knowledge Gets In
Different sources want different treatment. A researcher's X post is a few sentences with a dense link. A JSONL chat log is a sprawling multi-hour transcript with tool calls and backtracking. They fetch differently, chunk differently, and may want different retrieval models. So they get separate stores.
Automated Ingestion
Agent chat history and X posts work this way. Pull raw data, render it into readable markdown files, then index that readable markdown for search.
Chat history covers the coding agents I use day to day, Claude Code and Pi. Every session is captured: user messages, assistant replies, tool calls, and tool results.
Communications holds X posts. Eventually, this will hold all human-to-human communications.
Manual Synthesis
I need to feed agentkb information I find valuable. I do not just rely on magical AI smarts.
Consolidation: AgentKB has prompts that synthesize recent chats and X posts into wiki updates.
Ad hoc synthesis: When I see something worth capturing, I ask in the moment. For example, the end of a chat where I finally understood something, a GitHub repo that I found interesting, or a paper I want to pull ideas from. I transcribe what is interesting about the resources and why and ask an agent to add information to the wiki about it.
How Search Works
Search is hybrid keyword + semantic. The semantic side is the interesting part.
Most people think of retrieval as 1 vector per document, then compare queries to documents by the similarity between those vectors.
Late-interaction/Multi-Vector retrieval keeps one vector per token instead of one vector per document. A 400-token passage becomes 400 vectors. An 8-token query becomes 8 vectors. Each query token finds its best-matching document token, and those per-token scores sum into the final relevance score.
This means much better search, but more computation and memory. PLAID quantization is what makes that doable in practice. It clusters all token vectors, stores each token as a small residual from its nearest centroid. New data can be assigned to existing centroids for incremental indexing as the wiki grows.
Every search writes a trace to a local SQLite database: the original query, documents at each ranking stage, the final top-k, everything. I'll write more about retrieval evals in a later post.
The Privacy Part
The wiki started as a place for coding lessons and writing notes. It’s been expanding quickly.
I tried indexing my text messages with one person, with consent, as an experiment. I get some of the most candid, brutal, and valuable feedback and opinions from people over text messages. And it often significantly shapes how I build, so I know it’s high signal.
But privacy and security concerns led me to exclude text messages in my wiki while I give it more thought.
- It felt wrong to index private communication from someone who did not opt in.
- Asking feels awkward.
- If people know their texts might end up in a searchable store, I worry some may self-censor.
- My store becomes much more damaging if leaked, for me and for others.
I would not want my knowledge base to be public as some of it is embarrassing. But private text messages are worse. Those could damage trust, for me and for the people who were just texting a friend.
#4 worries me beyond just my use case. We accept that Verizon or iMessage servers could be breached. That risk is priced into the social contract of sending a text. Do we now need to accept that every person who can vibe-code will run their own private store of everyone they have ever talked to, with search over it, protected by however much security they happen to have based on their expertise and care?
macOS has security around my iOS Messages database on my Mac. The moment I pull text out into my plain-text wiki so it can be cross-referenced with coding notes and attached to the work where it applies, I open up new security challenges.
What Is Next
For AgentKB I want to add reference stores. For example, I want to track Pylate, NextPlaid, Codex github commits. And there are libraries I use all the time that I want indexed ready to go. For example, Pi’s extension docs.
For the whole solution Agentkb is used in Harpy, my Pi harness. I want to build an RLM tool into it that works with agentkb. Then release both the Pi harness (Harpy) and my multi-agent IDE (Siren).
If any of this is useful to you, take it. The repo is public, the docs are in the repo, and the easiest way to borrow an idea is to point your own agent at the source and ask.