mgrep with Founding Engineer Rui Huang
The Problem with grep for AI Agents
I hosted a talk with Rui Huang, a founding engineer at Mixedbread, about mgrep, a tool now essential to my workflow.
I sync every repo locally, automatically, all the time. I've seen companies replace production semantic search with Mixedbread's cloud service because it finds more relevant results and ranks them well.
Rui's talk focused on using their semantic search technology to build more effective coding agents.
This post covers key points from our conversation: the limits of tools
like grep, how mgrep provides a semantic alternative, and the
multi-vector and multimodal technology that powers it.
For an even deeper dive on what makes mgrep work and the research that
went into it, see Most RAG Systems Have a Context Problem
The Problem with grep for AI Agents
The "RAG is dead" headlines are bombastic but common. The argument: modern AI agents are so powerful they don't need semantic search. They can use basic tools like grep to find context with better results.
This argument targets older semantic search methods.

Agentic search using grep is powerful but has significant drawbacks.
Rui explained issues his team observed in long-running tasks.
1. It's Slow and Expensive.
grep is a pattern-matching tool. For a high-level task like "refactor
the authentication flow," an agent must guess keywords
(authentication, middleware, credentials) and run multiple tool
calls. That increases latency and token consumption, stuffing
the context window with noise.
2. It Degrades Quality.
More tool calls fill the context window with partial information.
The original intent gets diluted. Rui pointed out this is when you
see agents hallucinate or get stuck, responding with phrases like
"You're absolutely right" without making progress.
Faster feedback loops matter. When an agent uses fewer tokens and gets to the point faster, I can iterate and stay focused.
Introducing mgrep: Semantic Search for Code
Mixedbread's solution is mgrep, a command-line tool designed to be a
semantic version of grep. Instead of matching patterns, it understands
the intent behind a natural language query.
The Semantic Query
mgrep "how streaming is implemented"
The tool returns a list of relevant files with specific line numbers and
a similarity score, which helps the agent gauge the confidence of each
result.

This approach lets the agent progressively discover context instead of
stuffing multiple files into its prompt.
In Mixedbread's internal tests with Claude on complex coding tasks, mgrep delivered a large performance advantage:
-
53% fewer tokens used
-
48% faster response times
-
3.2x better quality responses
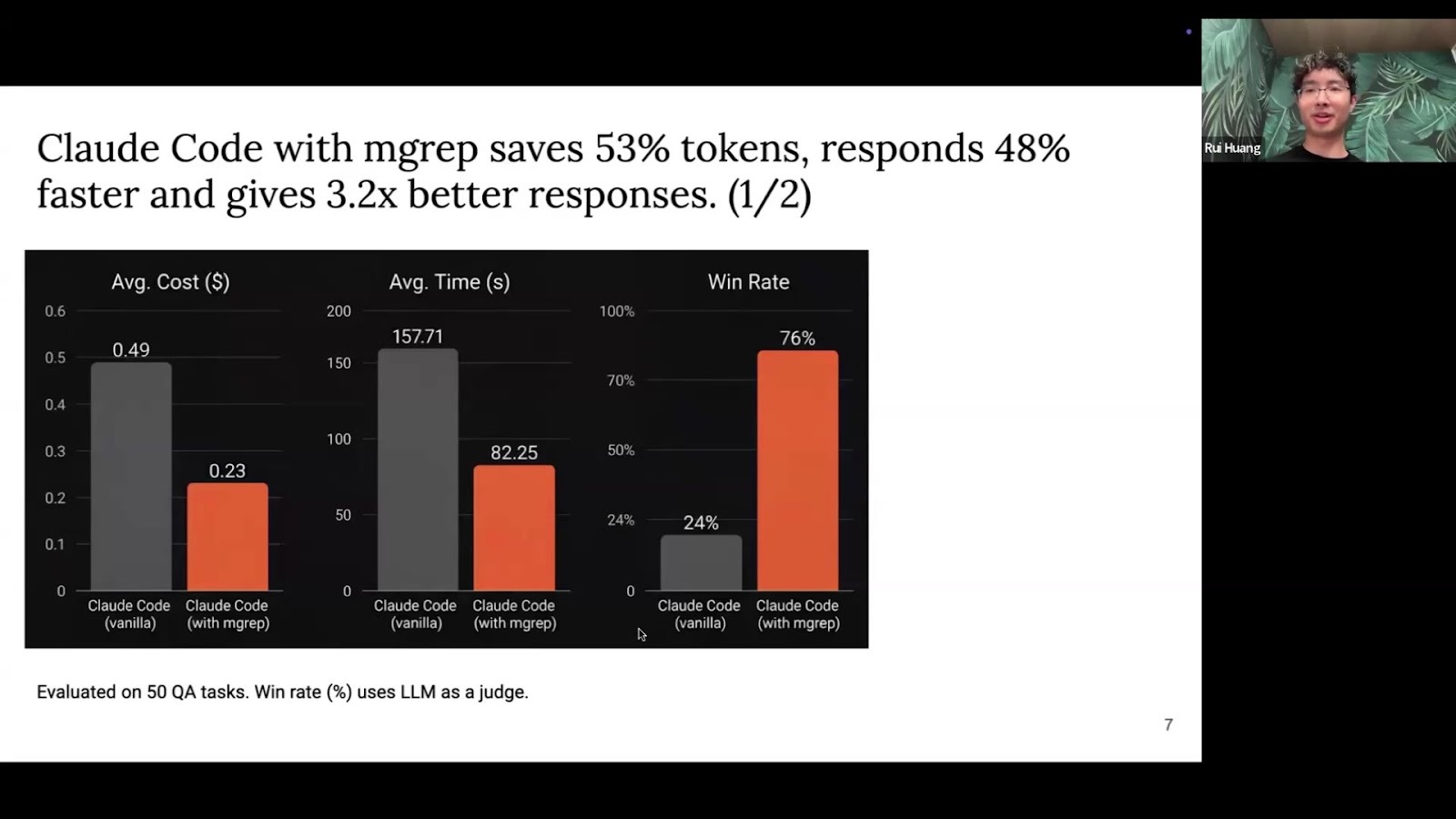
Note: I've seen similar gains in my own
experiments,
which is what inspired me to host this talk.
Live Demo: mgrep vs. grep
Rui demoed a playground that runs Claude side-by-side: standard grep
vs. mgrep. The task was to query the React codebase (over 6 million
tokens) with the question: "Explain how the useEffect hook works in
common patterns."
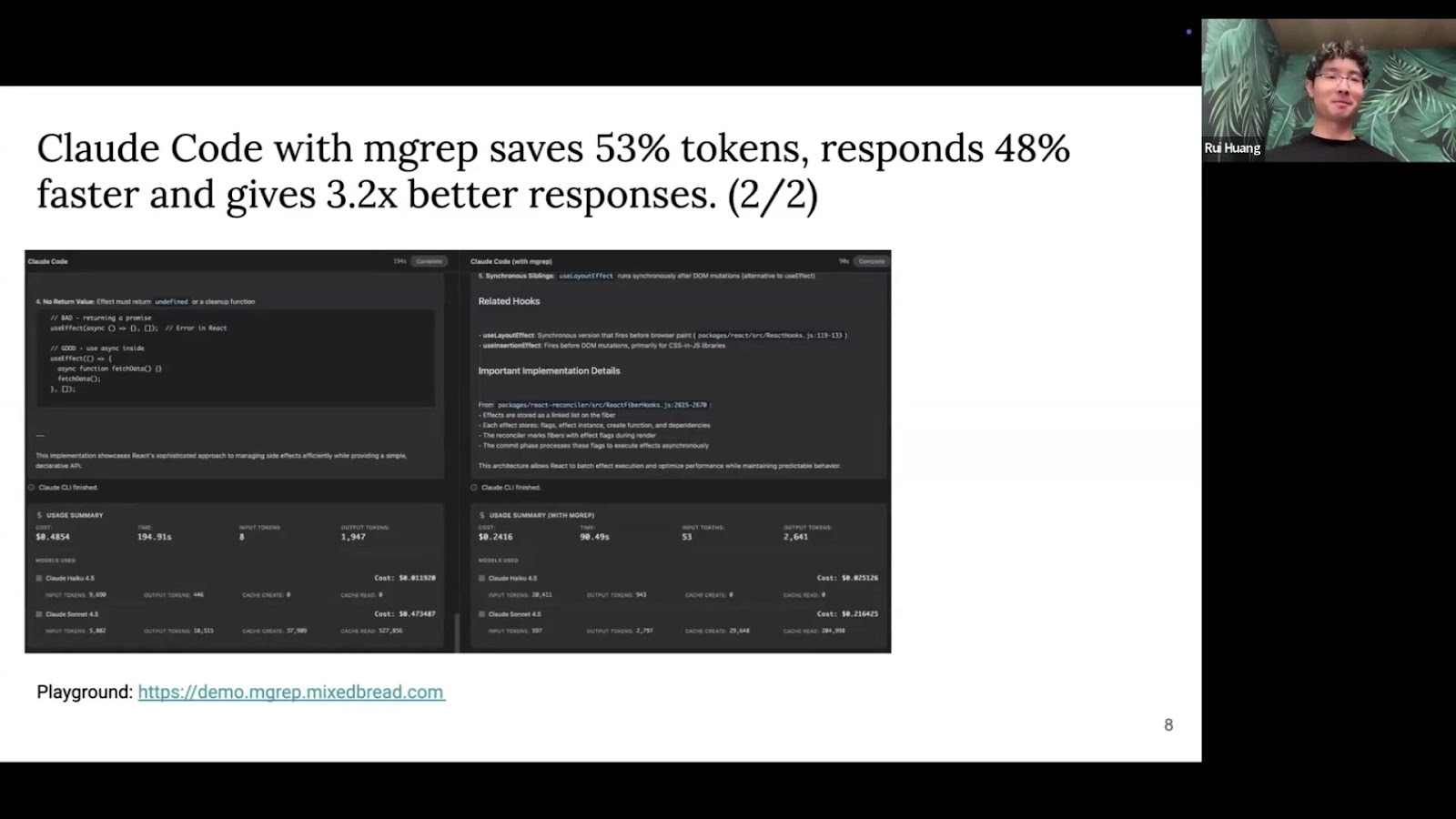
mgrep is complementary to grep, not a replacement. Agents get both
tools and can choose the right one: mgrep for semantic exploration and
grep for exact-match symbol searching.
Try the playground yourself to see
the difference without any setup.
Getting Started: Setup & Terminal Demo
mgrep syncs a local directory to a cloud-backed search index. Rui
walked through the setup.
First, install the tool via npm:
npm install -g @mixedbread/mgrep # or pnpm / bun
Then, log in to connect to your Mixedbread account:
mgrep login
Once set up, you can sync any directory. Rui used Andrej Karpathy's
nanogpt repository as an example. The watch command indexes the current
folder, respects .gitignore, and syncs to a remote Mixedbread store.
mgrep watch
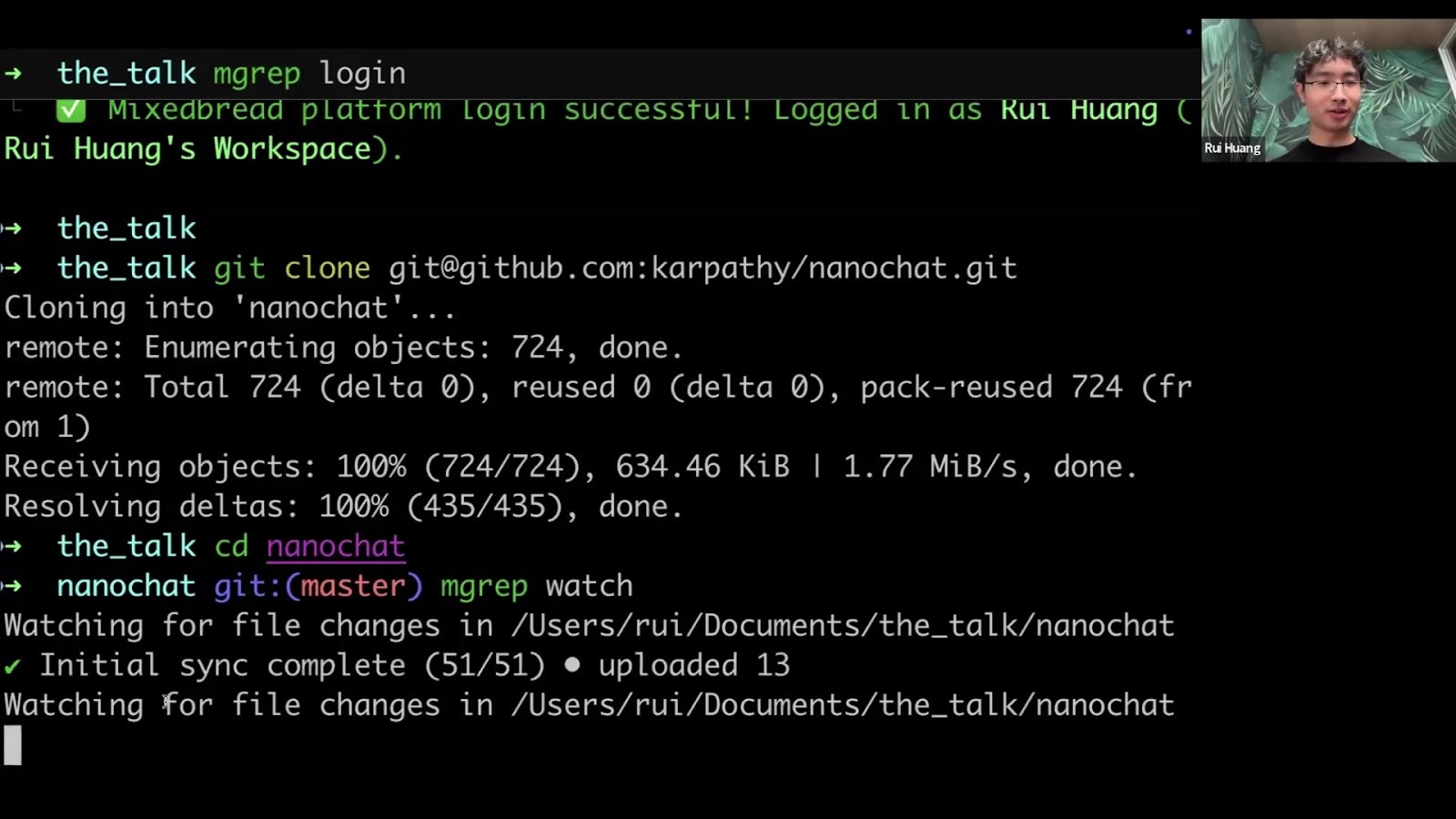
Ingestion is fast and cheap: the 60-million-token React codebase takes
about five minutes and costs $20 to index.
Once synced, you can query your code with natural language. mgrep also
includes a -a (--answer) flag that uses an LLM to return a direct
answer with citations.
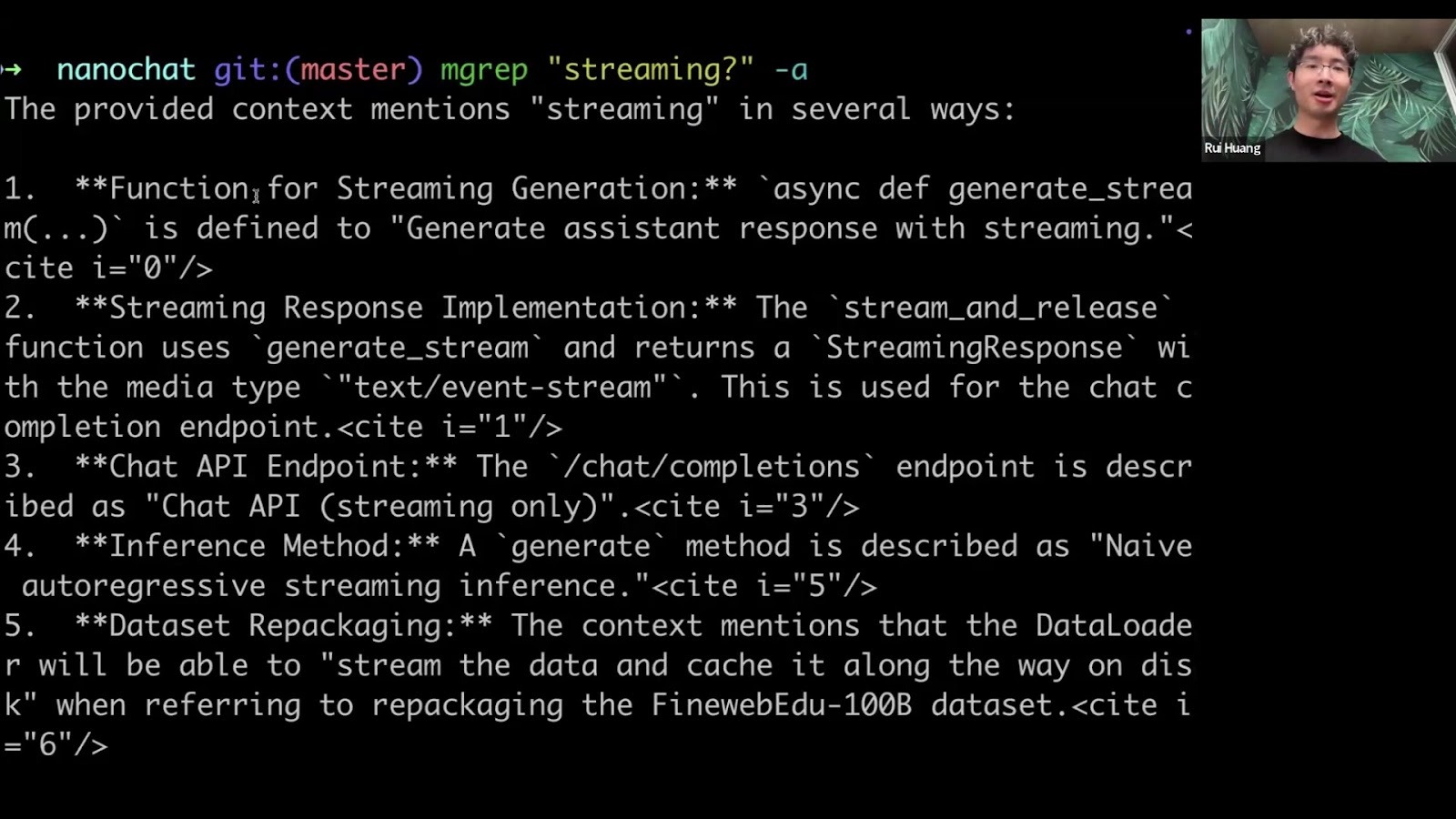
This gives the agent a concise summary, reducing the need to process
large file snippets.
Integrating mgrep with Coding Agents
While you can use mgrep manually, its core usage is in agent
integration. Mixedbread provides plugins for popular coding agents like
Claude Code.
A simple install command configures the agent to be aware of mgrep and
how to use it.
mgrep install-claude-code
This command sets up the necessary skills and prompts. The mgrep watch
process runs in the background during an agent session, keeping the
index up to date.
These plugins are wrappers around the mgrep CLI with a pre-written prompt. You can customize behavior by creating your own prompts in your agent's configuration files.
Under the Hood: Multi-Vector & Multimodal Search
mgrep is powered by the Mixedbread Search API. When you sync files,
they're sent to a Mixedbread store where the pipeline takes over.
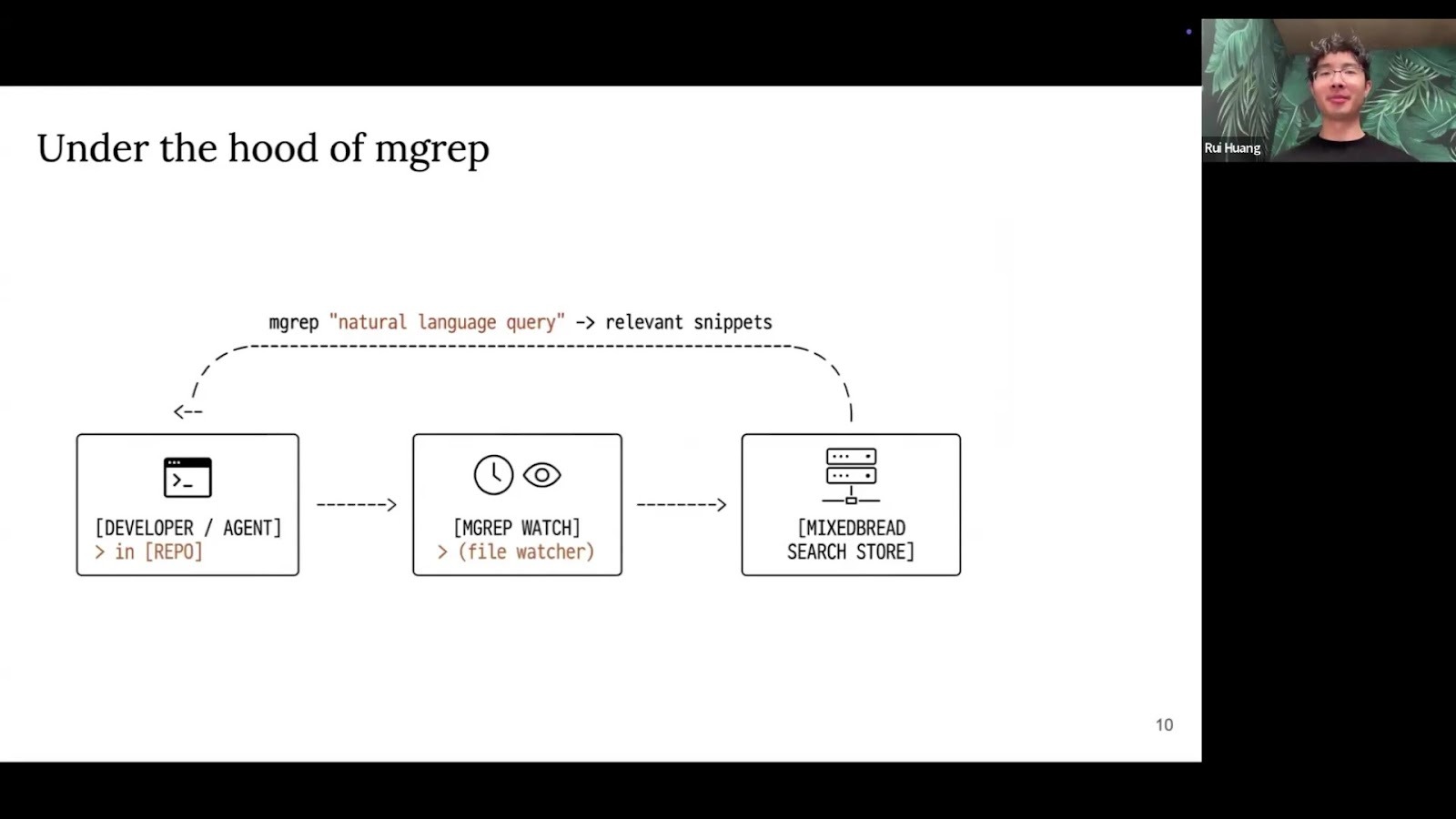
The service analyzes file types, applies chunking strategies (e.g., different logic for Markdown vs. code), and generates embeddings using state-of-the-art models.
The key innovation is multi-vector search. Traditional semantic
search creates one vector per chunk. Mixedbread represents every word
as its own vector, creating a richer, more granular representation.
Advanced
quantization
techniques make this approach scalable and affordable.
This system is also multimodal. It can natively index and search
images, videos, audio, and PDFs without transcribing them to text. Rui
demoed searches like "sad cat" and "angry cat."
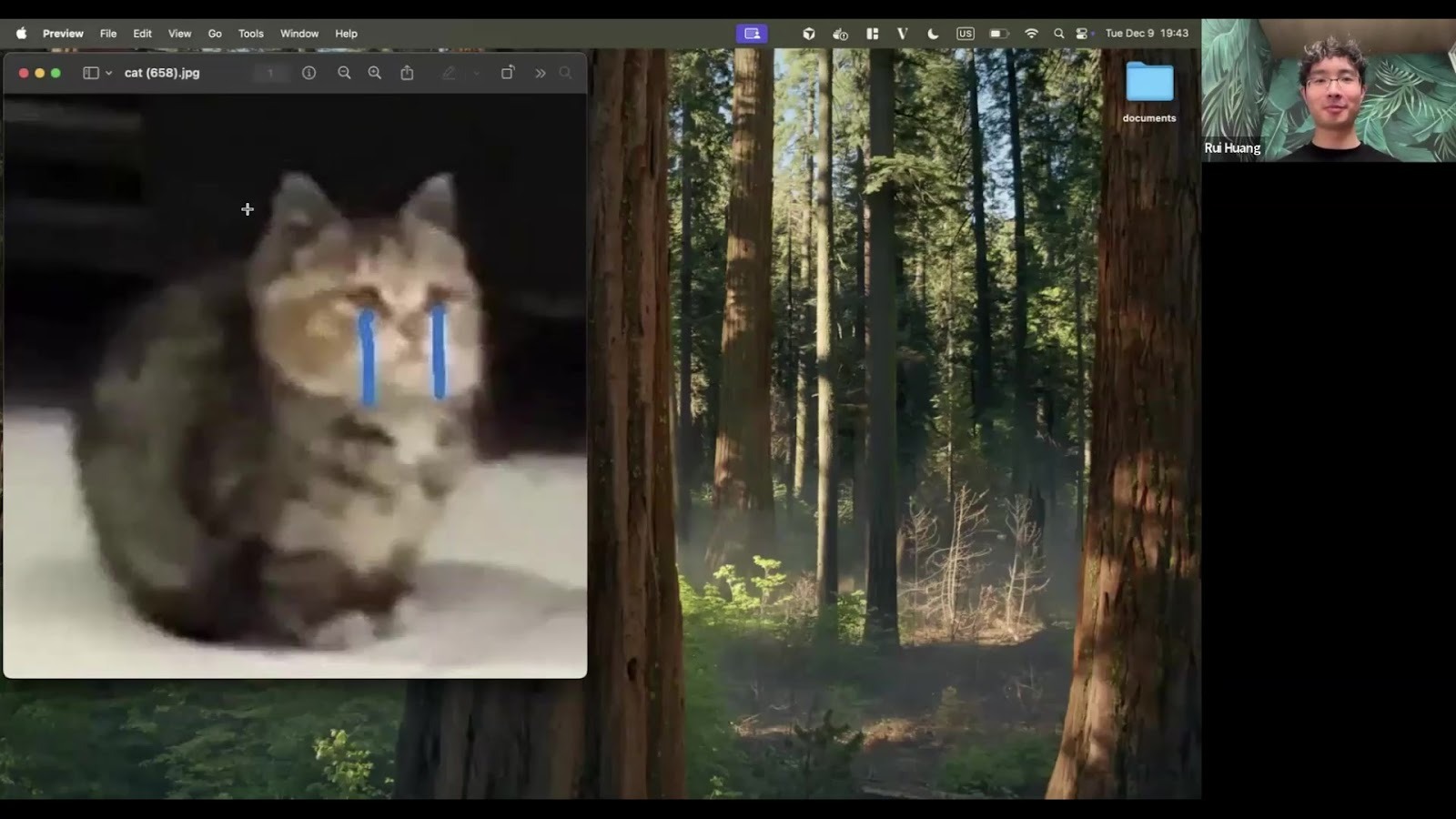
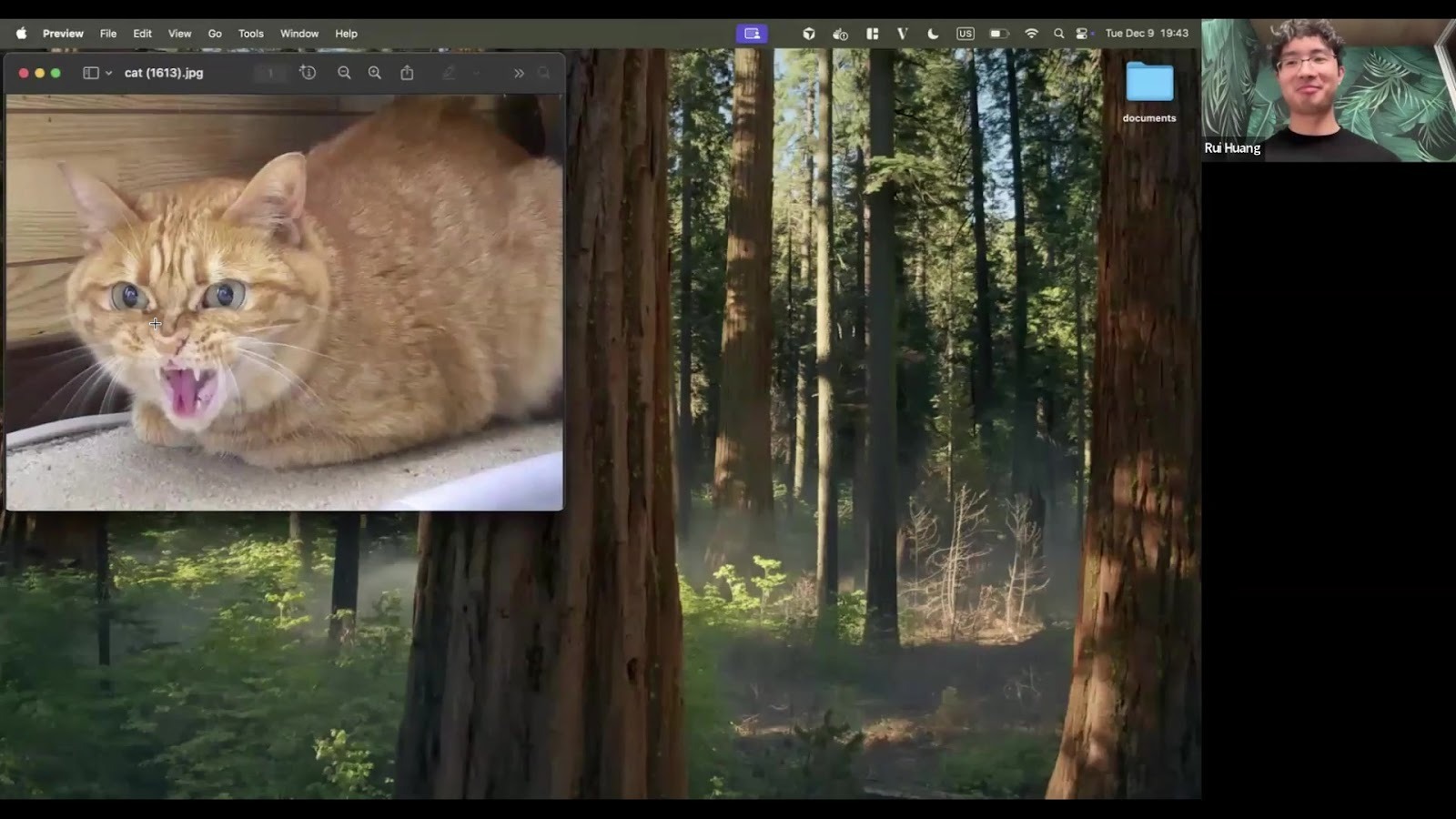
This helps codebases with diagrams, visual assets, or complex PDFs. Agents can find visual information that text-only tools like grep miss.
In legal domains, PDFs are often the source of truth for contracts. In e-commerce, product images are often the source of truth.
Conclusion: Give AI the Best Tools
Capable agents don't mean semantic search is dead. Agents need better search tools. Combining mgrep with grep gives agents a more powerful, efficient way to understand a codebase.

The key takeaways are:
-
Agentic search needs semantic search. Relying on grep alone is
slow, expensive, and leads to lower-quality results for complex tasks. -
Better tools lead to better agents.
mgrepimproves agent
performance by reducing token usage, increasing speed, and providing
more relevant context. -
The future is multimodal. As agents handle more data types, their
tools must keep up. Native search across code, PDFs, and images is a
significant advantage.
No matter how advanced agents become, their performance is constrained by tool quality. Search shouldn't be the bottleneck.
Q&A Highlights
We ended with audience questions:
-
Multilingual Support: Mixedbread's models are multilingual by
default, supporting languages like Arabic, Chinese, and Korean. Try
the search demo in different
languages. -
Cost: Indexing is priced per token. The full React codebase (6M+
tokens) costs roughly $20. The team is open to discounts at scale. -
Engineering Optimizations: Low latency comes from quantization
research and an optimized end-to-end pipeline. The team plans more
blog posts detailing the work.