Buying questions
Questions buyers ask
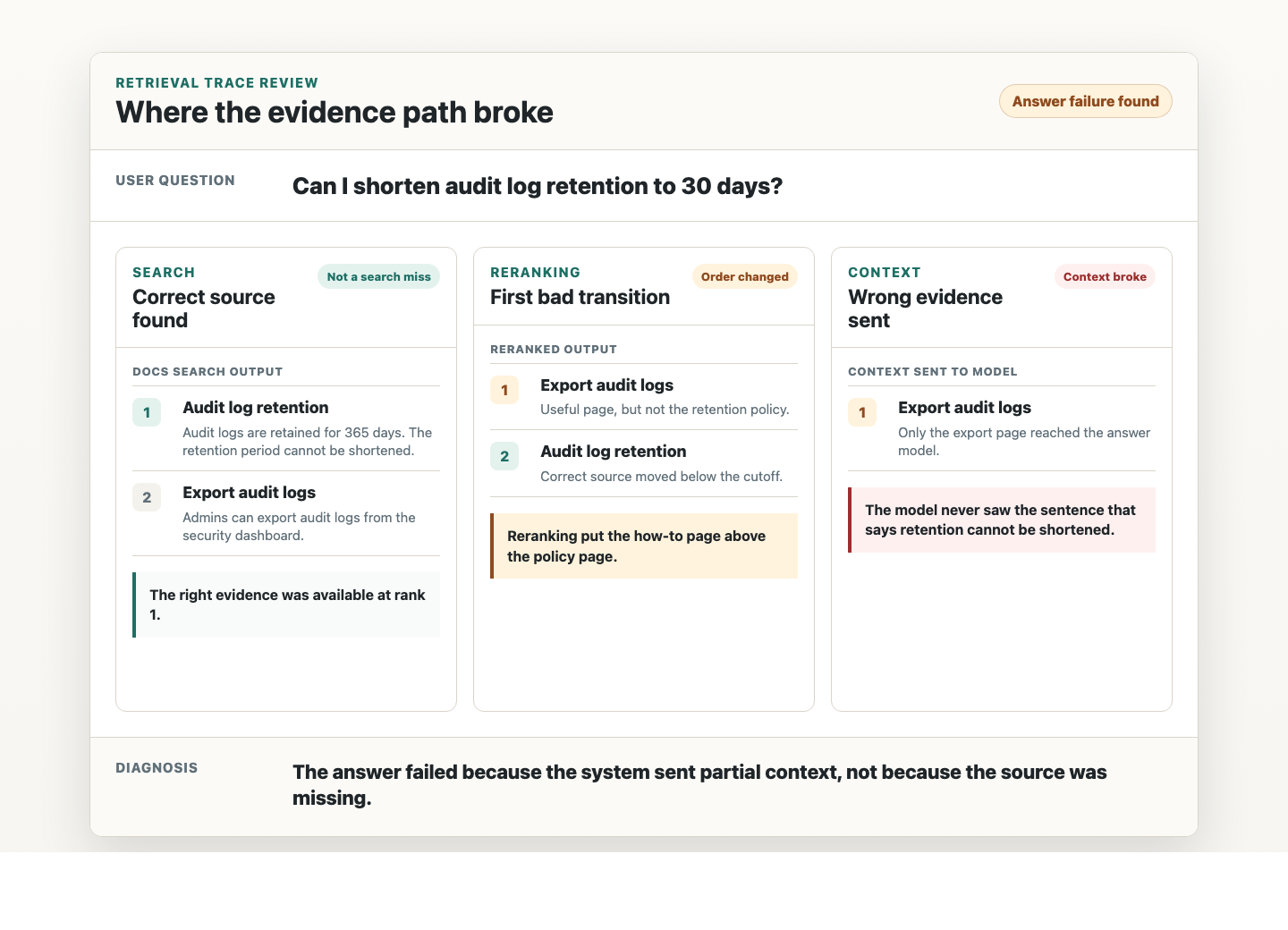
You do not need a perfect eval setup before we start. You need a real workflow, a real knowledge problem, and a team willing to inspect the evidence path.
Do we need evals or traces already?
No. If you have them, I will use them. If you do not, the first step is usually turning real user questions into a small eval set and a trace format the team can review.
Is this for existing products or new builds?
Both. Existing products usually start with an audit. New builds usually start with workflow design, source review, and a small retrieval prototype before the team commits to an architecture.
Can this work with private data?
Yes. The work can start from sanitized traces, representative source samples, or a private environment. The important part is preserving the shape of the workflow and the evidence path.
Is this only for RAG, or also agents?
Both. Agents are often context systems with memory, tools, state, and handoffs. If an agent depends on knowledge outside the prompt, we need to trace what it found, what it kept, what it used, and what it cited or acted on.
What do we get at the end of an audit?
You get the failure modes, the evidence behind them, the highest-impact fixes, and a 30-day plan. The goal is to leave with decisions the team can act on.
When is a sprint better than an audit?
Choose a sprint when the team already knows the retrieval layer needs implementation work: ingestion, chunking, hybrid search, reranking, citations, trace logging, or eval plumbing.
How technical does our team need to be?
I can work with product, engineering, data, or founder-led teams. The work is most useful when someone owns the product workflow and someone can make or review implementation changes.